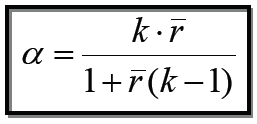

|
|
|
||||||||||
| ViLeS 0 > Datenmessung und -aufbereitung > Itemanalyse > Konzepte und Definitionen |
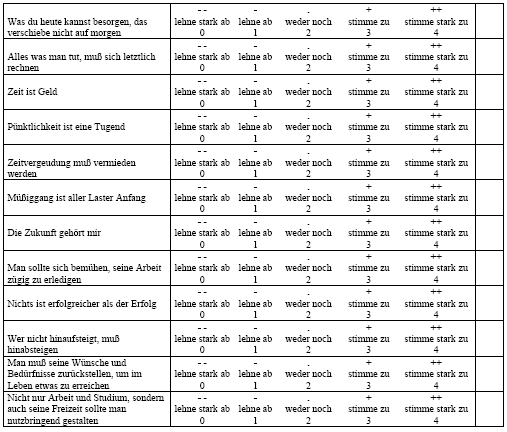
Konzepte und Definitionen im Modul ItemanalyseDie Itemanalyse (Reliabilitätsanalyse) ist nach der Eingangs- und Fehlerkontrolle der Daten ein erster Schritt zur Beurteilung und Aufbereitung der erzielten Untersuchungsergebnisse. Es geht dabei nicht darum, welche Informationen die Daten enthalten, sondern darum, ob einzelne Variablen überhaupt einen nennenswerten Informationsgehalt besitzen. Da die folgenden Ansätze zur Prüfung der Daten auf statistische Verfahren zurückgreifen, empfiehlt es sich parallel zur Bearbeitung dieses Moduls die entsprechenden Methoden der deskriptive Statistik (etwa die Module von ViLeS 1 über die eingearbeiteten Links) heranzuziehen oder dieses Modul vorerst zurückzustellen. Unter der Itemanalyse versteht man eine formale Analyse der einzelnen Variablen auf ihre Aussagefähigkeit und/oder ihren diagnostischen Wert und somit auf die Gültigkeit und Zuverlässigkeit der erhobenen Daten im Hinblick auf die Untersuchungsziele. Dabei wird sowohl der Informationsgehalt einer einzelnen Variablen wie deren Tauglichkeit in einem konkreten Untersuchungskontext, etwa innerhalb einer Testbatterie von Items geprüft, vgl. dazu etwa folgende Itembatterie (PE-Skala) aus einer Untersuchungen zur Frage, ob das Zeitmuster von Studierenden von den Prinzipien der protestantischen Ethik nach M. Weber geprägt ist zum Zeitbewusstsein und zur Zeitverwendung von Studierenden (vgl. Hans-Günther Heiland, Werner Schulte: Zeit und Studium.. Centaurus-Verlag, Herbolzheim 2002). Tabelle 3-16: Itembatterie zur PE-Skala 16. Wir haben eine Reihe von Aussagen aufgelistet, denen man zustimmen kann oder die man ablehnen kann. Lies bitte jede Aussage durch und kreuze eine Antwortkategorie an.
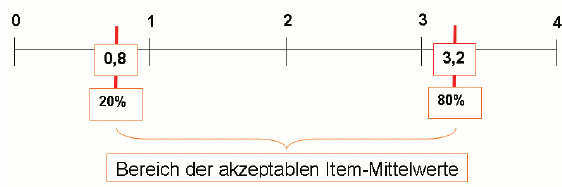
A) Die Analyse der Rohwerteverteilung der Items Eine erste Inspektion der Güte der Variablen zielt auf ihre Verteilungseigenschaften und bezieht sich auf Informationen über ihre Lage, Streuung und Verteilungsform. 1. Die rechnerische Analyse der Verteilungseigenschaften Bezüglich der Betrachtung der statistische Parameter der eindimensionalen Häufigkeitsverteilungen lassen sich die nachstehenden Erfordernisse formulieren: (a) zum rechnerischen Mittelwert: An den arithmetischen Mitteln kann man die Schwerpunkte der Verteilung ablesen. Items, die von gar keiner oder von allen Personen im Sinne des untersuchten Merkmals (hier: PE) beantwortet werden, bringen keine Information. Viele beobachtete Items sollen deshalb im mittleren Skalenbereich liegen und damit nur einige im höchsten Ablehnungsbereich oder im höchsten Zustimmungsbereich. Kein Mittelwert soll in eine Randklasse fallen. (b) zur Standardabweichung: Je geringer die Standardabweichung (Varianz) eines Items, desto schlechter ist (ceteris paribus) grundsätzlich sein Differenzierungsvermögen. Die Standardabweichung (bzw. die Varianz) als Maß der Variabilität gibt an, wie unterschiedlich die Probanden auf das Item reagiert haben. (c) Als weiteres Diagnoseinstrument kann man den Variationskoeffizienten berücksichtigen. Dabei bezieht man die Standardabweichung auf den dazugehörigen Mittelwert. 2. Die graphische Analyse der Verteilungseigenschaften Dazu eignen sich die graphische Darstellungen von Median und Quartilen in sog. Boxplots. Dazu wird die Merkmalsverteilung durch die Quartile in 4 gleich große Segmente aufgeteilt. Die sog. Boxes stellen eine Visualisierung der Streuung der Merkmalswerte dar. Das erste Quartil bildet die linke, das dritte Quartil die rechte Grenze der Box. Der Median (das 2. Quartil, dicker Balken) deutet die Mitte der Verteilung an und kann ebenfalls zur Beurteilung der Güte der Items herangezogen werden werden. Der Quartilsabstand ist dann der Abstand zwischen zwei Items, in deren Antwortbereich die mittleren 50% der Beobachtungen fallen. Je größer er ist, desto breiter sind die Boxplot. Je größer die Streuung, desto eher haben die Items in bezug auf die PE-Einstellung diskriminierende Qualität. B) Die Analyse der Schwierigkeit eines Items Ein Item ist dann schwierig, wenn es nur von wenigen im Sinne der gewünschten Eigenschaft zustimmend beantwortet wird. Dabei wird die Schwierigkeit durch den relativen Anteil der Befragten ausgedrückt, die das Item im Sinne des Untersuchungsmerkmals (man spricht hier von Schlüsselrichtung), d.h. im bezug auf Tab.-1 als deutlich PE-geprägt, beantworten. Ziel ist es, Items mittlerer Schwierigkeit zu konstruieren, weil sie dann eher geeignet sind, möglichst viele Befragten voneinander zu unterscheiden. Es gibt zwei Möglichkeiten, die akzeptablen Items über die Item-Schwierigkeit zu operationalisieren. Einmal über die bereits unter 1. durchgeführte Betrachtung der Itemmittelwerte, zum zweiten über die Berechnung eines Schwierigkeitsindexes. 1. Bestimmung der Schwierigkeit über den Mittelwert Ein optimales Differenzierungsvermögen haben Items mit einem arithmetische Mittelwert im 20% bis 80%-Bereich der Skala von 0 bis 4 (Faustregel) Abbildung 3-15: Differenzierungsvermögen von Items
2. Berechnung eines Schwierigkeitsindexes Der Schwierigkeits-Index ist als Anteil der von den n befragte Personen erreichten (beobachteten) Itemwerte zu den gesamt erreichbaren Itemwerten definiert und wird mit folgender Formel berechnet:
Die Summe der angekreuzten Item-Werte der einzelnen Personen (Summenwerte der Items) wird in Bezug zum insgesamt möglichen Punktwert der Items gesetzt, wobei xi= der angekreuzter Itemwert der Person i und xmax= der maximal mögliche Punktwert. D.h. bei n = 100 und 4 = höchste Ausprägung des Items gilt: xmax = 400. C) Die Trennschärfeanalyse 1. Definition und Operationalsierung der Trennschärfe Trennschärfe bedeutet ursprünglich das Ausmaß in dem ein Item die Merkmalsträger nach dem fraglichen Merkmal (hier PE-Einstellungsmuster) differenziert. Da man das Merkmal nicht kennt, nimmt man stellvertretend für das Merkmal den Gesamttest, weil man davon ausgeht, dass er das Merkmal am besten repräsentiert. Der Gesamttestwert ergibt sich für die einzelnen Teilnehmer als Summe deren einzelner Items. Die Trennschärfeanalyse zeigt, ob ein einzelnes Item von den Befragten in der Regel in Schlüsselrichtung der PE-Einstellung beantwortet wird. Operational ist die Trennschärfe somit auf der Basis eines Regressions- Zusammenhangs des Items mit dem Gesamttestwert definiert. Items haben eine hohe Trennschärfe, wenn das PE-Einstellungsmuster über eine hohe Korrelation des Items mit einem Wert des Gesamttestwertes identifizierbar ist. Die Berechnung erfolgt bei intervallskalierten Items über die Produkt-Moment-Korrelation (Korrelationskoeffizient nach Bravais-Pearson) 2. Analyse der Trennschärfekoeffizienten Die ermittelten Korrelationskeffizienten werden als Trennschärfekoeffizienten interpretiert. Sie können Werte zwischen 0 und 1 annehmen. Ein hoher Wert bei bei einem Item deutet daraufhin, dass dieses Item sehr gute Diskriminierungseigenschaften hat. Ein Trennschärfekoeffizient um 0 bringt zum Ausdruck, dass Personen mit hoher PE-Einstellung und solche mit geringer PE-Einstellung das Item in etwa gleicher Weise beantworten. Dies weist auf eine geringe Diskriminierungsfähigkeit des Items hin. Items mit einem Trennschärfekoeffizienten < 0,2 können verworfen werden. D) Analyse des Zusammenhangs zwischen Trennschärfekoeffizient und Schwierigkeitsindex Eine maximale Trennschärfe der Items ist das primäre Kriterium der Itemselektion. Items mit einem Trennschärfe koeffizienten um 0 oder gar kleiner als 0 sollten ausgeschieden werden. Items mit geringer Trennschärfe sollten zusätzlich nach ihrer Schwierigkeit beurteilt werden. Im Rahmen dieser weiteren Selektionsbemühungen werden die Werte der beiden Variablen Trennschärfekoeffizient und Schwierigkeitsindex in einem Streuungdiagramm dargestellt (vgl. dazu Abb. 3-20 im nächsten Abschnitt). Problematisch sind dabei die Items, die neben einer geringen Trennschärfe auch noch eine geringe oder zu hohe Schwierigkeit aufweisen. E) Cronbach’s Alpha Die Berechnung von Cronbach’s Alpha stellt die gebräuchlichste Methode der Reliabilitätseinschätzung, d.h. der Messung der Reproduzierbarkeit von Messergebnissen dar. Die interne Konsistenz der Item-Messwerte wird über folgende Formel nach Cronbach (1951) errechnet:
Dabei bedeuten k die Anzahl der Items und Schaubild 3-3: Richtlinien zur Einschätzung der Alpha-Werte
F) Die Skalenanalyse Mit der Skalenanalyse wird die Eindimensionalität bzw. Homogenität eines Items geprüft. Es geht dabei um folgende Fragen:
Man muss also beispielsweise begründen können, dass es für die Bedeutung eines Testwerts unerheblich ist, durch welche Einzelleistungen er zustande gekommen ist. Die Berechnung eines Gesamtwertes als Summe von Einzel-Items gilt dann als gerechtfertigt, wenn empirisch nachgewiesen wird, dass alle Items „dasselbe” messen.
|
letzte Änderung am 5.4.2019 um 4:24 Uhr.
Adresse dieser Seite (evtl. in mehrere Zeilen zerteilt)
http://viles.uni-oldenburg.de/navtest/viles0/kapitel03_Datenmessung~~lund~~l-aufbereitung/modul03_Itemanalyse/ebene01_Konzepte~~lund~~lDefinitionen/03__03__01__
01.php3
|
| Feedback | Copyright | Übersicht | Druckversion | Log-Out | Sitemap | Nächster Arbeitsschritt | |