|
Datenquellen und Arbeitsanregungen im Modul X-4 Eigene Analysen und Interpretationen
1. Die Datenquellen
a) Die Typen von ordinalen Daten
Bei der Analyse von Zusammenhängen zwischen ordinal skalierten Variablen sind zwei Typen von Daten zu unterscheiden: zum Einen individuelle Rangreihen mit den Ausprägungen 1.... N und kategoriale Daten mit den Ausprägungen 1....k. Für die erste Art von Daten stehen die Rangkorrelationsanalyse und die Konkordanzanalyse für Einzeldaten zur Verfügung, für die zweite die Konkordanzanalyse für klassierte Daten.
Von der Verfahrensseite her ist einzuschränken, dass die in ViLeS vorliegenden Tools nur für rangskalierte Datensätze - und das auch nur für eine geringe Anzahl von Fällen (N ≤ 7) - entsprechende Angebote beinhalten, so dass für diesen Datentyp eigentlich nur eine manuelle Berechnung oder die Analysepakete SPSS und bedingt Excel in Frage kommen.
Für kategoriale Daten stehen ebenfalls nur manuelle Berechnungen oder der Einsatz von Analyseprogrammen zur Verfügung.
Wie anhand der praktischen Beispiele zu sehen war, ist die manuelle Berechnung der Koeffizienten bei beide Datentypen sehr aufwändig und bei umfangreichen Rangreihen oder Kreuztabellen eigentlich ausgeschlossen. Letztlich bleibt dann für eigene Berechnungen nur, die Rangreihen bzw. die Merkmalskategorien (weiter) zusammenzufassen oder auf den Einsatz von Analyseprogrammen zurückzugreifen.
b) Die Auswahl der Daten
Die Verwendung von Rangreihen
Rangskalierte Daten stehen i.A. nur für besondere Sachverhalte zur Verfügung, so etwa bei der Positionierung von Individuen oder Mannschaften im sportlichen Bereich (z.B. Tennisrangplätze, Bundesligatabellen) oder für wirtschaftliche Phänomene (z.B. Rangplätze im internationalen Vergleich der Exporte oder der Arbeitslosenquoten).
Auch wenn diese Vergleichs-Reihen meist in metrischen Skalen vorliegen, lassen sie sich leicht manuell in Rangreihen umrechnen. So könnten als Basis einer Analyse der Stabilität von Märkten, die Marktanteile von Versicherungsgesellschaften in den Jahren 1960 und 2000 (vgl. Modul VI-2, Tab. 6-10) nach Rängen geordnet einer Konkordanz- oder Rangkorrelationanalyse unterzogen werden.
-
Auf die Möglichkeit, Individualdaten aus Datensätzen mit Hilfe von SPSS in Rangreihen umzuwandeln, wurde im vorangegangenen Arbeitsschritt hingewiesen.
Die Verwendung von kategorialen Daten
Kategoriale Datenquellen können entweder beliebige, vorgegebene Kreuztabellen auf ordinaler Basis oder die kategorialen Variablen in einen Datensatz sein. Sinnvoll ist es, auf die beiden Möglichkeiten zurückgreifen.
Im ersten Fall Fall legen Sie der Analyse Kreuztabellen zugrunde, die Sie den Modulen VIII - IX oder anderen statistischen Untersuchungen aus Ihren Studienunterlagen bzw. den Medien entnehmen können.
Finden Sie dazu
Beispiele für Kreuztabelle von ordinal-skalierte (oder metrische klassierte) Variablen zwischen denen Sie
einen Zusammenhang vermuten und berechnen Sie dazu die verschiedenen Zusammenhangsmaße mit den unter X-2 vorgeschlagenen Instrumenten.
Wenn Sie mit einem Datensatze arbeiten, können Sie
die Beispielsdatensätze aus dem ViLeS-Material zur deskriptiven Statistik benutzen,
den Demonstrationsdatensatz aus dem Modul VIII durch SHIFT+LINKSKLICK auf das Diskettensymbol herunterladen:

-
Am besten arbeite Sie jedoch mit einem eigenen Datensatz.
2. Anregungen zur eigenen Analyse und zur Wahl des Analyseinstruments
Im Folgenden werden Ihnen weitere Hinweise auf die Möglichkeiten eigener Datenanalysen auf der Basis ordinalskalierter Daten gegeben. Auf den Aufwand, die Analyseergebnisse per Hand zu erstellen, wurde bereits hingewiesen. Deshalb beziehen sich die nachfolgenden Hinweise im Wesentlichen auf die Analysepakete Excel und SPSS.
Achten Sie bei der Analyse vor allem darauf, Ihre Ergebnisse auch inhaltlich zu prüfen und zu interpretieren.
Berücksichtigen Sie bitte auch, dass Sie Maßzahlen für ein niedrigeres Skalenniveau stets auch für Variablen auf höherem Skalenniveau verwenden können (nicht jedoch umgekehrt!). Wenn Sie eine Kreuztabelle der zweidimensionalen Häufigkeitsverteilung zweier ordinalskalierter Variablen erstellen, können Sie für diese daher auch Maße auf der Basis von Chi-Quadrat verwenden und sich so die unterschiedliche Aussagekraft vor Augen führen.
a) Eigene Analysen mit Excel
Excel kennt keine Maße zur Zusammenhangsanalyse von Ordinaldaten.
Allerdings kann es die Arbeit der Rangeinteilung erleichtern. Man setzt dazu den Cursor in eine Spalte neben der zu analysierenden Spalte und trägt im Analysefenster RANG(A5,A5:A505) ein, wobei A5 der Standort der mit einem Rang zu versehenden Zahl ist und A5:A505 der Bereich, welcher vollständig nach Rängen sortiert werden soll. Durch Anklicken des Rechtecks der markierten Ergebniszelle und Herunterziehen ergeben sich die restlichen Rangeinteilungen.
Um den Spearmansche Rangkorrelationskoeffizient zu ermitteln, werden die entstehenden "Rangspalten" voneinander abgezogen, quadriert und aufsummiert.
Das Ergebnis lässt sich in die
Formel 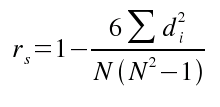 einsetzen. einsetzen.
Dazu führt man folgende Operation aus: rs = 1 - (6 * E506/(501(501^2-1))).
b) Eigene Analysen mit SPSS
SPSS erlaubt die Berechnung aller hier behandelter Maßzahlen. Allerdings sollten Sie die Verfahren zur Konkordanzanalyse und zur Rangkorrelationsanalyse erst nach einer genauen Untersuchung der Datenreihen einsetzten.
|