| Druckversion: | | Nach dem Drucken: | | und zurück zum Dokument |
Sollte das Drucken mit diesem Schaltknopf nicht funktionieren, nutzen Sie bitte die Druckfunktion in Ihrem Browser: Menü Datei -> Drucken
Datenquellen und Arbeitsanregungen im Modul VIII-3 Eigene Analysen und Interpretationen
1. Die Datenquellen
Im Folgenden werden Möglichkeiten aufgezeigt, eigene Daten oder Beispieldatensätze für eine zweidimensionale Analyse aufzubereiten. Als Beispieldatensätze stehen verschiedene Datensätze in unterschiedlichen Formaten zur Verfügung:
-
ein kleiner Demonstrationsdatensatz zur Analyse des Zusammenhangs zwischen Arbeitsstress und psychischer Konstitution aus dem Modul VIII-2, "Beispiele und Aufgaben":
Tabelle 8-16: Arbeitsstress und psychischer Konstitution
|
Psychische Konstitution
|
Arbeitsstress
|
|
normal
|
hoch
|
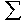
|
|
labil
|
3
|
16
|
19
|
|
teils/teils
|
22
|
18
|
40
|
|
stabil
|
32
|
9
|
41
|
|
sehr stabil
|
5
|
1
|
6
|
|
|
62
|
44
|
106
|
 SPSS-Datei durch SHIFT+LINKSKLICK auf das Diskettensymbol herunterladen!
SPSS-Datei durch SHIFT+LINKSKLICK auf das Diskettensymbol herunterladen!
-
der Partizipationsdatensatz und
-
der Mikrozensusdatensatz
Hinweise und Links zum Partizipationsdatensatz und zum Mikrozensusdatensatz finden Sie hier.
2. Anregungen zur inhaltlichen Analyse
a) Zum Arbeiten mit dem Demonstrationsdatensatz
Für die obige Kontingenztabelle 8-16 können Sie mit der
zugrunde liegenden SPSS-Datei eine Indifferenztabelle berechnen und die Daten auf verschiedene Weise graphisch darstellen.
b) Zum Arbeiten mit dem Partizipationsdatensatz
Zur tabellarischen und graphischen Analyse zweidimensionaler Daten eignen sich neben den bereits herangezogenen Variablen Ausbildung und Status die Variable Geschlecht sowie die klassierten Variablen zum Partizipationsprofil und -potential. Damit lassen sich eine Vielzahl von interessanten Zusammenhängen untersuchen, so z.B. die Einflüsse der Variablen Status, Ausbildung oder Geschlecht auf die Beteiligungsvariablen.
c) Zum Arbeiten mit dem Mikrozensusdatensatz
Auch hier müssen vorab zwei Variablen ausgewählt werden: eine Untersuchungsvariable, z.B. das Einkommen (klassiert), die Miete (klassiert), das Bildungsniveau u.ä., und eine Erklärungsvariable, welche die Struktur der Untersuchungsvariablen nach den Kategorien der Erklärungsvariablen (Geschlecht, Bildungsniveau, Einkommen) ausdifferenziert.
Die Konstellationen (Einkommen-Bildungsniveau, Einkommen-Geschlecht, Bildungsniveau-Geschlecht, Miete-Einkommen o.ä.) stellen vorerst nur Möglichkeiten oder Hypothesen für einen Zusammenhang dar. Die tabellarische Gegenüberstellung und die grafische Darstellung geben dann erste Hinweise auf das Vorliegen eines tatsächlichen statistischen Zusammenhanges.
1. Die Auswertungsprogramme
Die tabellarischen und grafischen Aufbereitungen lassen sich wieder mit den Analyseprogrammen Excel, Web-Stat oder SPSS durchführen. Hinweise zu deren Einsatz werden in den folgenden Ausführungen gegeben.
a) Eigene Analysen mit Excel
In Excel lassen sich Kontingenztabellen sehr leicht über Extras->Pivot-Table herstellen. Ausgegangen wird von der Datenmatrix, die keinen Abstand zu ihren Spaltenüberschriften aufweist. Der Cursor wird in die Zelle der am linken Rand stehenden Überschrift gesetzt. Anschließend ruft man das genannte Modul auf und wählt "Fertig stellen". Es erscheint eine noch unbesetzte Tabelle und das Makro "Pivot-Table", in dem alle Variablen mit ihrer Überschrift genannt sind. Nun kann man wahlweise zwei Variablen jeden Skalenniveaus in die Summenspalte bzw. Summenzeile der Tabelle ziehen. Um sich bedingte und unbedingte Häufigkeiten anzeigen zu lassen, muss eine der Variablen nochmalig ins Innere der Tabelle gezogen werden.
Für einen besseren Umgang mit der Pivottabelle erscheint es sinnvoll, diese nur als Werte zu kopieren und die Kopie weiter zu analysieren. Dies geschieht über Markieren der Pivottabelle -> Bearbeiten -> Kopieren -> Cursor in ein neues Feld -> Bearbeiten -> Inhalte einfügen -> Werte -> OK.
Grafische Darstellungsformen, in denen die Ausprägungen einer Variablen als Kategorien auf die Abszisse gelangen und die in diesen Kategorien (grafisch Balken) vorkommenden Ausprägungen der anderen Variablen anteilsmäßig dargestellt werden, erreicht man über Markierung der bedingten Häufigkeiten innerhalb der Tabelle -> Diagrammassistent -> Säule -> dritte Abbildung der obersten Optionen -> Fertigstellen.
b) Eigene Analysen mit StatCrunch
Über folgenden Link können Sie das einfache interaktive Statistikprogramm Web-Stat aufrufen. Dort können Sie überStat -> Contingency eine Kontingenztabelle eingeben und sich den zugehörigen Chi-Quadrat-Wert ausrechnen lassen.
c) Eigene Analysen mit SPSS
Dazu benötigen Sie einen Zugang zu SPSS entweder auf Ihrem Rechner oder auf dem Intranet der Universität und einen eigenen Datensatz oder die oben verlinkten Demonstrationsdatensätze.
letzte Änderung am 5.4.2019 um 4:24 Uhr.
Adresse dieser Seite (evtl. in mehrere Zeilen zerteilt)
http://viles.uni-oldenburg.de/navtest/viles1/kapitel08_Zweidimensionale~~lH~~aeufigkeitsverteilungen/modul03_Eigene~~lAnalysen~~lund~~lInterpretationen/ebene02_
Arbeit~~lmit~~lAuswertungsprogrammen/08__03__02__01.php3