|
Konzepte und Definitionen im Modul II-1 Die Datengrundlage
1. Die Aufbereitung statistischer Daten
a) Die Rohdaten
Die Aufbereitung
statistischer Daten setzt i.A. an den noch unbearbeiteten Befragungsergebnissen der einzelnen Probanden und der
daraus entstandenen Urliste an. In der Urliste wird jede Einzelangabe als spezifische Ausprägung einer Variablen erfasst.
Resultiert die Urliste aus einer online-Befragung, liegen die Daten als Datei mit numerischen oder alphanumerischen Eintragungen vor. In einer standardisierten schriftlichen Befragung ergeben sich sowohl numerische wie begriffliche Angaben, die u.U. noch codiert und als numerische Werte in eine elektronische Datei eingegeben werden müssen.
b) Die Signier- und Plausibilitätskontrollen
Die ersten Schritte der Datenaufbereitung bestehen in der Datenbereinigung. Im Zuge einer Signier- und Plausibilitätsprüfung sollen dabei anhand einer vorläufigen tabellarischen Auflistung
fehlerhafte Werte identifiziert,
fehlende Werte (etwa mit "-1" oder "99") gekennzeichnet,
-
Fälle mit vielen Antwortverweigerungen eliminiert,
-
in zweidimensionalen Häufigkeitstabellen (vgl. dazu Kap. vII) unplausible Merkmalskombinationen (z.B. Status: arbeitslos/Erwerbseinkommen 3000 EUR) überprüft und
alpha-numerischen Angaben (etwa zum Beruf oder zum Wirtschaftszweig) vereinheitlicht und mittels eines systematischen Schlüsselverzeichnisses in gebräuchliche Klassifikationen (etwa der amtlichen Statistik) überführt werden.
2. Die Bereitstellung statistischer Daten
Nach der Datenbereinigung stehen die Informationen in Form von Datenmatrizen und Metadaten zur Analyse bereit.
a) Die Datenmatrix
Die abstrakte Datenmatrix ordnet die statistischen Informationen zeilenweise den einzelnen Personen oder Objekten (i = 1...N) zu. Die Merkmale (Variablen X j , j = 1...m) sind spaltenweise aneinander gefügt (vgl. Abb. 2-5). Das Merkmal j des Objektes i wird als X ij bezeichnet.
Abbildung 2-5: Die abstrakte Datenmatrix
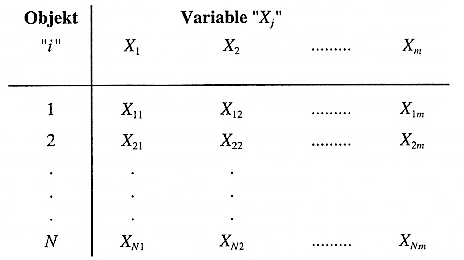
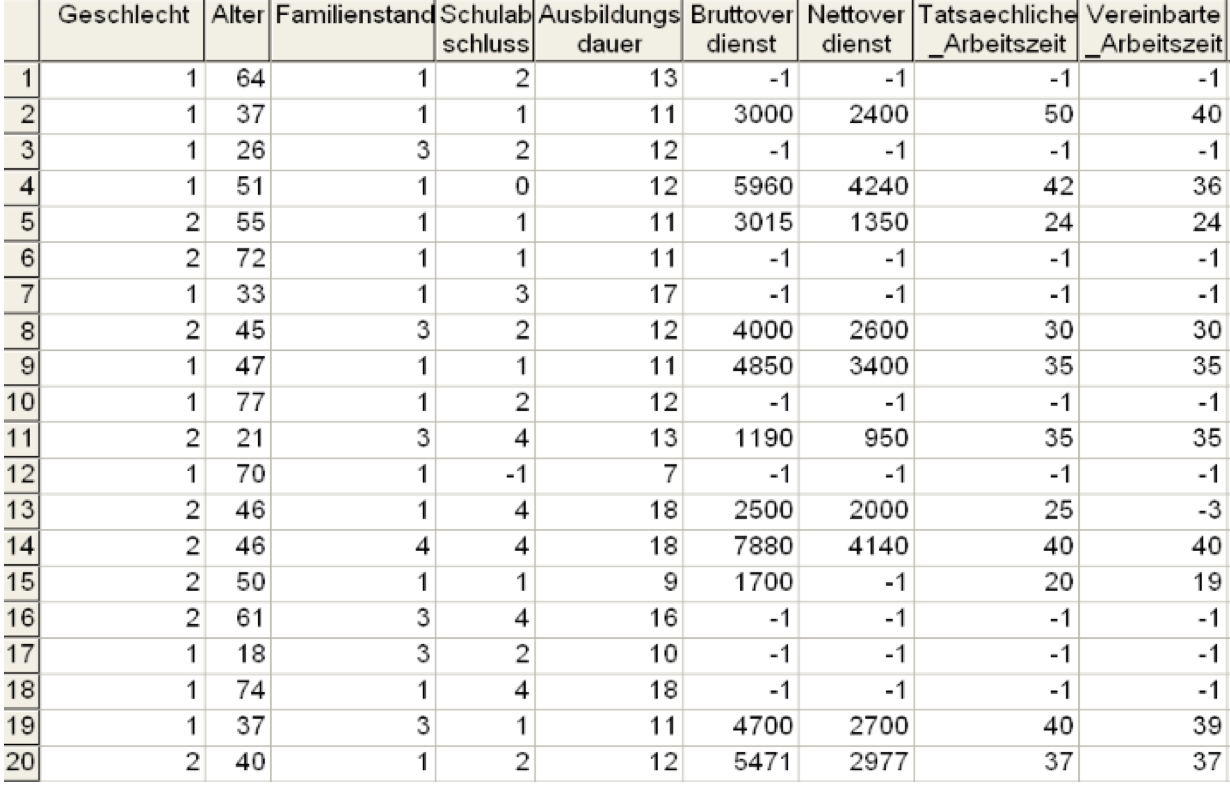
Die Informationen in der konkreten Datenmatrix (vgl. Abb. 2-6) bestehen nur aus ein- oder mehrstelligen Ziffern und sind als solche nur bedingt verständlich, da entweder deren Bedeutung (etwa bei nominalen oder ordinalen Werten) oder deren Maßstab (bei metrischen Werten) unklar bleibt. Wenn die Variablen in der Kopfzeile der Matrix nur abstrakt benannt sind ( X 1 , X 2 usw.), fehlt der Datenmatrix jegliche empirische Aussage.
Abbildung 2-6: Die konkrete Datenmatrix
b) Die Metadaten
Damit der Inhalt der Datenmatrix verständlich wird, sind die Inhalte der Datenmatrix durch die Metadaten zu beschreiben. Diese beinhalten:
-
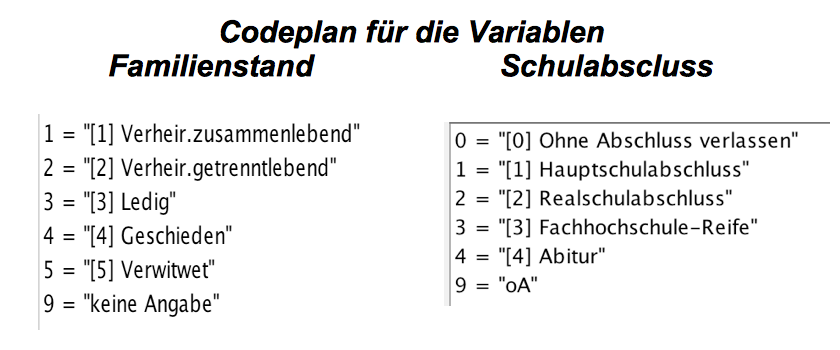
einmal die empirische Bedeutung der einzelnen Variablen und die Benennung der Maßstäbe bzw. die Zuordnung der Codeziffern zu empirischen Merkmalsausprägungen (vgl. Abb. 2-7). Damit die Auswertungsergebnisse nachvollziehbar sind, sind diese Metadaten als Variablenbeschreibungen Teil der elektronischen Datendatei.
Abbildung 2-7: Codepläne
-
Zum anderen sind darin wichtige Informationen zur Befragung selbst wie
enthalten
|